
In the wake of boasts by symptom-checking apps that their AI can diagnose medical conditions better than humans, a peer-reviewed study published in BMJ Open recently debunked those claims. After going through a series of clinical vignettes, general practitioners listed the correct diagnosis in their top three suggestions 82% of the time, significantly more than the apps did, on average.
But between the individual apps, results ranged widely range in accuracy and safety. Apps also varied significantly in the scope of conditions they could assess. It’s worth noting that the study was funded by Ada Health, a Berlin-based company making one of the symptom-checkers that was evaluated.


Inside an Automated Healthcare Practice: Redesigning Care Around People, Not Paperwork
By reducing administrative burden and redesigning workflows around human needs, it creates space for what matters most: connection between clinicians and patients.
When physicians entered symptoms into its app, Ada said its system rendered the correct result 70.5% of the time. Other apps performed as follows:
- Buoy: 43%
- K Health: 36%
- WebMD: 35.5%
- Mediktor: 35%
- Babylon: 32%
- Symptomate: 27.5%
- MD: 23.5%
Coverage limitations
A large reason for the variation between the apps was that many did not provide suggestions at all. For example, some symptom checkers are not intended to be used by people under a certain age, or who are pregnant. In other cases, the presented problem was not recognized by the app, or it would not suggest a condition for users with severe symptoms.


Top 7 Modern AI-Powered EAP Providers for Global Workforces in 2026
Discover the top AI-powered EAP providers for 2026. Compare platforms like Kyan Health and Spring Health on triage speed, global reach, and clinical quality to transform workforce wellbeing.
While age restrictions wouldn’t affect an app’s accuracy for adults, other limitations could be more concerning, the authors of the study wrote. For example, the inability to search for certain symptoms, or excluding certain mental health conditions or pregnancy would be more problematic for some users.
Babylon, whose symptom checker and telehealth service are used by the UK’s National Health Service, didn’t offer a suggestion for roughly half of the cases in the study.
“Babylon’s symptom checker does not include condition suggestions for some groups, like children and pregnant women, or certain conditions, such as cancers. In the study, the accuracy score for suggested conditions is based on the ‘required-answer’ approach, which meant we got marked down for providing no answer,” a Babylon spokesperson wrote in an email. “However, for the vignettes where our app did provide a suggested condition, there was no significant difference between us and the best performing app.”
The company also emphasized that its app is not intended to be used as a diagnostic tool.
Apps were also evaluated for safety based on whether their recommendation matched the urgency advice of each diagnosis, such as whether a patient needed to be seen within the next day. Most erred on the side of caution, but in a few cases, suggestions were potentially unsafe.
Physicians, on the whole, made recommendations that were much closer to the “gold standard” in this case. Of the apps, Babylon’s matched the most closely with the recommended urgency of care. Here’s how they performed:
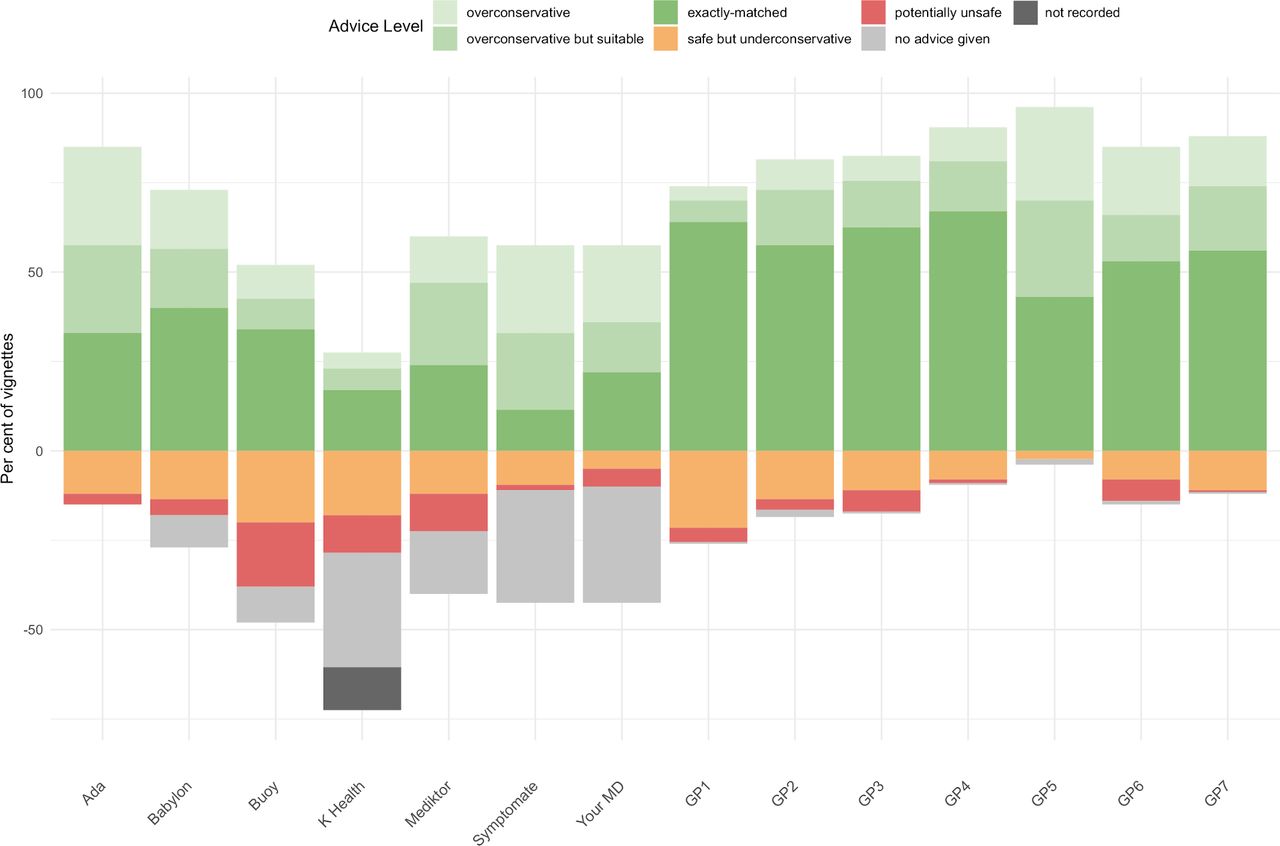
Symptom-checker apps were evaluated to see if their triage urgency suggestions matched recommended diagnoses in a paper recently published in BMJ Open.
Study design
“Our study included a rigorous design process conducted by experienced clinical researchers, data scientists and health policy experts, with the methodology and analysis peer-reviewed by independent and experienced primary care physicians and medical experts at UCL in the UK and Brown University in the US,” Ada’s clinical evaluation director, Stephen Gilbert, wrote in an email. “To ensure a fair comparison, our team used a large number of ‘clinical vignettes,’ fictional patients generated from a mix of real patient experiences gleaned from the UK’s NHS 111 telephone triage service and from the many years’ combined experience of the research team.”
A separate group of primary care physicians decided on the “gold standard” diagnosis for each scenario.
The apps were tested between November and December of last year, and were each evaluated using 50 randomly assigned vignettes.
For instance, one of the vignettes was for an 8-year-old boy with complaints of abdominal pain and fever, with a recommended diagnosis of appendicitis. Another was for a 63-year-old woman who has been unable to move her shoulder for a day, and is experiencing shoulder pain, with a recommended diagnosis of frozen shoulder.
The last major analysis of symptom checkers, which was published in 2015, found that they listed the correct diagnosis first just 34% of the time, and provided the appropriate triage advice in 57% of patient evaluations.
But so far, all of these tests have been based on vignettes. In the future, apps should be evaluated based on their performance with real patient data, researchers suggested.
Photo credit: venimo, Getty Images